This scenario is a mid-range cost DR solution. For example, you can use cross-region replication for S3. S3s duplicates the data to multiple locations within a region by default, creating high durability. You will want to make use of AWS disaster recovery management tools, many of which can be had with a few clicks of your cloud provider console. For instance, consider the Simple Storage Service which has a Durability SLA of 99.999999999% and Availability SLA of 99.99% for a given year. Availability = 100% Multiple of dependent Redundant Services Availability, Example: if two EC2 instances ( SLA 99.99% ) of the same applications are deployed in different availability zones then the availability is 100% (0.001% * 0.001%) = 99.999999%. If we need to lower the values of RTO and RPO, then the cost of running the application will be higher. A Region is a physical location in the world that has multiple Availability Zones. This spreads the changes across several tables. Within EC2, for example, you have choices between Amazon Machine Images (AMI) or EBS snapshots. Read about AWS disaster recovery best practices to learn more about effective protection and recovery methods: https://www.nakivo.com/blog/aws-disaster-recovery-best-practices, NAKIVO is a US-based corporation dedicated to developing the ultimate VM backup and site recovery solution: https://www.nakivo.com. Well be discussing auto recovery and other pilot light recovery in the next part of this series, It presents you with my previous projects, Amazon Web Service Certified Solutions Architect Professional & Devops Engineer, Digital Designer, How to Install Pycharm IDE for Windows and Setting The Virtual Environment, TCP BBR - Exploring TCP congestion control, Infrastructure Automation using AWS CloudFormation, Presentation of Chapter 5 from my book Extending Power BI with Python and R, Designing software users trust, moving towards intelligent advocacy, What is a modernized Mainframe to you? For long term data storage, we use Amazon Glacier, which has the same durability as Amazon S3, but the difference is that the cost is lower compared to S3. You can subsequently create local volumes or Amazon EBS volumes from these snapshots. 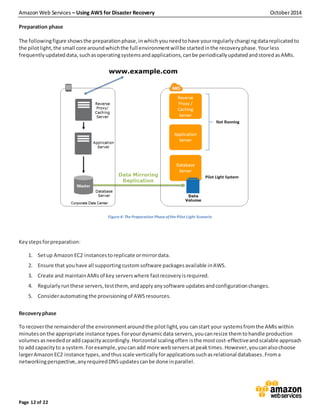 Resize existing database/data store instances to process the increased traffic, Add additional database/data store instances to give the DR site resilience in the data tier. There are several strategies that we can use for disaster recovery of our on-premise data center using AWS infrastructure: The Backup and Restore scenario is an entry level form of disaster recovery on AWS. This approach is the most suitable one in the event that you dont have a DR plan. Often, such plans are insufficiently tested or poorly documented. Warm Standby is an extended version of Pilot Light. Availability Zones consist of one or more discrete data centers, each with redundant power, networking, and connectivity housed in separate facilities. *)\",\"StartWindowMinutes\":480,\"TargetBackupVaultName\":\"BackupVault\",\"Lifecycle\":{\"DeleteAfterDays\":35}}]}" --backup-plan-tags workload=APP, $ aws backup put-backup-vault-notifications --region us-east-1 --backup-vault-name BackupVault --backup-vault-events BACKUP_JOB_COMPLETED RESTORE_JOB_COMPLETED --sns-topic-arn arn:aws:sns:us-east-1:464392538707:BackupNotificationTopic-default-region-infrastructure, $ aws backup get-backup-vault-notifications --backup-vault-name BackupVault --region us-east-1, $ aws cloudformation delete-stack --stack-name default-region-infrastructure, $ aws backup delete-backup-plan --backup-plan-id a56a1fc9-b176-46b8-80b8-a7fa5679ec1f, $ aws backup delete-recovery-point --backup-vault-name BackupVault --recovery-point-arn arn:aws:ec2:us-east-1::image/ami-089590ebcfd373c24, $ aws backup delete-backup-vault --backup-vault-name BackupVault, $ aws logs delete-log-group --log-group-name /aws/lambda/RestoreTestFunction-default-region-infrastructure, https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip, ParameterKey=NotificationEmail,ParameterValue=zhaofeng8711@gmail.com, In terms of system, we will be using RHEL 8.3 by Oracle Virtual Box on Windows 10 using putty. All of our applications require Business Continuity. In this post, well take a look at what disaster recovery means, compare traditional disaster recovery versus that in the cloud, and explore essential AWS services for your disaster recovery plan. Most importantly, AWS allows a pay as you use (OPEX) model, so we dont have to spend a lot in advance. Backup phase:In most traditional environments, data is backed up to tape and sent off-site regularly taking longer time to restore the system in the event of a disruption or disaster, Amazon S3 can be used to backup the data and perform a quick restore and is also available from any location, Data backed up then can be used to quickly restore and create Compute and Database instances. There are also custom solutions available via the AWS marketplace, including options ranging from pilot light to hot standby., Establish the In-House Communication Network, Re-assign developers from your in-house team to monitor and fine-tune your infrastructure, and run DR scenarios, Hire a DevOps support team, who will manage your IT support 24/7, report on new findings and continuously optimize your infrastructure performance, What matters most is testing, testing and testing. Ensure an appropriate retention policy for this data. SLA is an agreement between providers in the AWS and the client (user). aws whte The following figure shows the recovery phase of the pilot light scenario. Around 10 minutes later, job was done, Right after, restore jobs will be triggered by Lambda Function. Objects are optimized for infrequent access, for which retrieval times of several hours are adequate. serverless harshavardhan ghorpade enthusiast Disaster Recovery (DR) enables recovery or continuation of vital technology infrastructure and systems following a natural or human-induced disaster. If were talking about on-premise centers, a disaster recovery plan is expensive to maintain and implement. Consider automating the provisioning of AWS resources. This is a suitable solution for core business-critical functions and in cases where RTO and RPO need to be measured in minutes. AWS Import/Export Accelerates moving large amounts of data into and out of AWS by using portable storage devices for transport. Snapshots of Amazon EBS volumes, Amazon RDS databases, and Amazon Redshift data warehouses can be stored in Amazon S3. So this approach reduces RTO and RPO but the cost will be high due to the fact that an alternate system is running 24/7. You can also use global tables in DynamoDB to deploy a multi-region multi-master database. RPO will be the time since the last backup. Disaster Recovery scenarios can be implemented with the Primary infrastructure running in your data center in conjunction with the AWS. You should know how much system downtime your organization can afford before suffering irreparable monetary losses.Therefore, calculating your recovery time objective is critical for a successful recovery plan. Depending on these metrics, AWS offers 4 basic techniques for back-up and disaster recovery. A detailed and up-to-date AWS disaster recovery plan can help you recover and restore the backup data from the cloud environment with minimal downtime. Lets say you migrated to the cloud using the rehosting method and you use EC2 instances for your application. aws You can use the snapshots as the starting point for new Amazon EBS volumes. As we all know, on-premise server has long been there store the critical data of an organization. While planning and preparing a DR plan, well need to think about the AWS services we can use. Traffic is cut over to the AWS infrastructure by updating DNS, and all traffic and supporting data queries are supported by the AWS infrastructure. A business continuity plan is a process definition when a disruption of services occur. Elastic Load Balancing automatically distributes incoming application traffic across multiple Amazon EC2 instances. An on-premise disaster recovery plan can be challenging to document, test, and verify, especially if you have multiple clients on a single infrastructure. What is AWS Amplify, and how does it work? Amazon Cloud Formation can be used to automate the provisioning of these services. RPO and RTO. For example, with AWS you can maintain a Pilot Light by configuring and running the most critical core elements of your system in AWS. The AWS Import/Export service bypasses the internet and transfers your data directly onto and off of storage devices using Amazons high-speed internal network. disaster recovery aws medium amazonwebservices pdf source The following figure shows the preparation phase for a warm standby solution, in which an on-site solution and an AWS solution run side-by-side. For example, you can implement detective measures such as server and network monitoring software. Amazon S3 is the destination for data backup. 10 minutes after, the restore job was done, Email received for restore job completion, While backing up we created a brand new EC2. Recover Point Objective (RPO) is the maximum targeted period in which data might be lost from an IT service due to a major incident. Love podcasts or audiobooks? Corrective measure as remediation tools can help restore a system after a disaster. (Part 2), Connecting a Bastion Server to an AWS PostgreSQL Server via SSH Tunnel, EMQX + NLB (AWS) + EKSPreserve Client IP, Configuring DFS Namespaces for Amazon FSx for Windows file servers, Zero Downtime MySQL replication across continents, speed up using AWS Lightsail, $ aws cloudformation create-stack --template-body file://default-region-infrastructure.yaml --stack-name default-region-infrastructure --parameters, $ aws backup create-backup-vault --backup-vault-name BackupVault, $ aws backup create-backup-plan --backup-plan "{\"BackupPlanName\":\"Backupplan\",\"Rules\":[{\"RuleName\":\"DailyBackups\",\"ScheduleExpression\":\"cron(0 5 * * ? As such, its adequate for protecting resources. Notes: In case you are unable to install RHEL 8.3 successfully, please find solutions here. But there are also strengths that come with that additional cost.
Resize existing database/data store instances to process the increased traffic, Add additional database/data store instances to give the DR site resilience in the data tier. There are several strategies that we can use for disaster recovery of our on-premise data center using AWS infrastructure: The Backup and Restore scenario is an entry level form of disaster recovery on AWS. This approach is the most suitable one in the event that you dont have a DR plan. Often, such plans are insufficiently tested or poorly documented. Warm Standby is an extended version of Pilot Light. Availability Zones consist of one or more discrete data centers, each with redundant power, networking, and connectivity housed in separate facilities. *)\",\"StartWindowMinutes\":480,\"TargetBackupVaultName\":\"BackupVault\",\"Lifecycle\":{\"DeleteAfterDays\":35}}]}" --backup-plan-tags workload=APP, $ aws backup put-backup-vault-notifications --region us-east-1 --backup-vault-name BackupVault --backup-vault-events BACKUP_JOB_COMPLETED RESTORE_JOB_COMPLETED --sns-topic-arn arn:aws:sns:us-east-1:464392538707:BackupNotificationTopic-default-region-infrastructure, $ aws backup get-backup-vault-notifications --backup-vault-name BackupVault --region us-east-1, $ aws cloudformation delete-stack --stack-name default-region-infrastructure, $ aws backup delete-backup-plan --backup-plan-id a56a1fc9-b176-46b8-80b8-a7fa5679ec1f, $ aws backup delete-recovery-point --backup-vault-name BackupVault --recovery-point-arn arn:aws:ec2:us-east-1::image/ami-089590ebcfd373c24, $ aws backup delete-backup-vault --backup-vault-name BackupVault, $ aws logs delete-log-group --log-group-name /aws/lambda/RestoreTestFunction-default-region-infrastructure, https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip, ParameterKey=NotificationEmail,ParameterValue=zhaofeng8711@gmail.com, In terms of system, we will be using RHEL 8.3 by Oracle Virtual Box on Windows 10 using putty. All of our applications require Business Continuity. In this post, well take a look at what disaster recovery means, compare traditional disaster recovery versus that in the cloud, and explore essential AWS services for your disaster recovery plan. Most importantly, AWS allows a pay as you use (OPEX) model, so we dont have to spend a lot in advance. Backup phase:In most traditional environments, data is backed up to tape and sent off-site regularly taking longer time to restore the system in the event of a disruption or disaster, Amazon S3 can be used to backup the data and perform a quick restore and is also available from any location, Data backed up then can be used to quickly restore and create Compute and Database instances. There are also custom solutions available via the AWS marketplace, including options ranging from pilot light to hot standby., Establish the In-House Communication Network, Re-assign developers from your in-house team to monitor and fine-tune your infrastructure, and run DR scenarios, Hire a DevOps support team, who will manage your IT support 24/7, report on new findings and continuously optimize your infrastructure performance, What matters most is testing, testing and testing. Ensure an appropriate retention policy for this data. SLA is an agreement between providers in the AWS and the client (user). aws whte The following figure shows the recovery phase of the pilot light scenario. Around 10 minutes later, job was done, Right after, restore jobs will be triggered by Lambda Function. Objects are optimized for infrequent access, for which retrieval times of several hours are adequate. serverless harshavardhan ghorpade enthusiast Disaster Recovery (DR) enables recovery or continuation of vital technology infrastructure and systems following a natural or human-induced disaster. If were talking about on-premise centers, a disaster recovery plan is expensive to maintain and implement. Consider automating the provisioning of AWS resources. This is a suitable solution for core business-critical functions and in cases where RTO and RPO need to be measured in minutes. AWS Import/Export Accelerates moving large amounts of data into and out of AWS by using portable storage devices for transport. Snapshots of Amazon EBS volumes, Amazon RDS databases, and Amazon Redshift data warehouses can be stored in Amazon S3. So this approach reduces RTO and RPO but the cost will be high due to the fact that an alternate system is running 24/7. You can also use global tables in DynamoDB to deploy a multi-region multi-master database. RPO will be the time since the last backup. Disaster Recovery scenarios can be implemented with the Primary infrastructure running in your data center in conjunction with the AWS. You should know how much system downtime your organization can afford before suffering irreparable monetary losses.Therefore, calculating your recovery time objective is critical for a successful recovery plan. Depending on these metrics, AWS offers 4 basic techniques for back-up and disaster recovery. A detailed and up-to-date AWS disaster recovery plan can help you recover and restore the backup data from the cloud environment with minimal downtime. Lets say you migrated to the cloud using the rehosting method and you use EC2 instances for your application. aws You can use the snapshots as the starting point for new Amazon EBS volumes. As we all know, on-premise server has long been there store the critical data of an organization. While planning and preparing a DR plan, well need to think about the AWS services we can use. Traffic is cut over to the AWS infrastructure by updating DNS, and all traffic and supporting data queries are supported by the AWS infrastructure. A business continuity plan is a process definition when a disruption of services occur. Elastic Load Balancing automatically distributes incoming application traffic across multiple Amazon EC2 instances. An on-premise disaster recovery plan can be challenging to document, test, and verify, especially if you have multiple clients on a single infrastructure. What is AWS Amplify, and how does it work? Amazon Cloud Formation can be used to automate the provisioning of these services. RPO and RTO. For example, with AWS you can maintain a Pilot Light by configuring and running the most critical core elements of your system in AWS. The AWS Import/Export service bypasses the internet and transfers your data directly onto and off of storage devices using Amazons high-speed internal network. disaster recovery aws medium amazonwebservices pdf source The following figure shows the preparation phase for a warm standby solution, in which an on-site solution and an AWS solution run side-by-side. For example, you can implement detective measures such as server and network monitoring software. Amazon S3 is the destination for data backup. 10 minutes after, the restore job was done, Email received for restore job completion, While backing up we created a brand new EC2. Recover Point Objective (RPO) is the maximum targeted period in which data might be lost from an IT service due to a major incident. Love podcasts or audiobooks? Corrective measure as remediation tools can help restore a system after a disaster. (Part 2), Connecting a Bastion Server to an AWS PostgreSQL Server via SSH Tunnel, EMQX + NLB (AWS) + EKSPreserve Client IP, Configuring DFS Namespaces for Amazon FSx for Windows file servers, Zero Downtime MySQL replication across continents, speed up using AWS Lightsail, $ aws cloudformation create-stack --template-body file://default-region-infrastructure.yaml --stack-name default-region-infrastructure --parameters, $ aws backup create-backup-vault --backup-vault-name BackupVault, $ aws backup create-backup-plan --backup-plan "{\"BackupPlanName\":\"Backupplan\",\"Rules\":[{\"RuleName\":\"DailyBackups\",\"ScheduleExpression\":\"cron(0 5 * * ? As such, its adequate for protecting resources. Notes: In case you are unable to install RHEL 8.3 successfully, please find solutions here. But there are also strengths that come with that additional cost.
In the context of DR, the ability to rapidly create virtual machines that you can control is critical. These are some of the key features and services that you should consider when creating your Disaster Recovery plan: AWS Regions and Availability Zones The AWS Cloud infrastructure is built around Regions and Availability Zones (AZs). And, you can protect your data for long-term durability because snapshots are stored within Amazon S3.
These solutions may be offered by third-party vendors for example, AWS partners with companies such as N2WS and Cloudberrylab that offer disaster recovery solutions tailored to AWS. Objects are redundantly stored on multiple devices across multiple facilities within a region and are designed to provide a durability of 99.999999999% (11 9s).
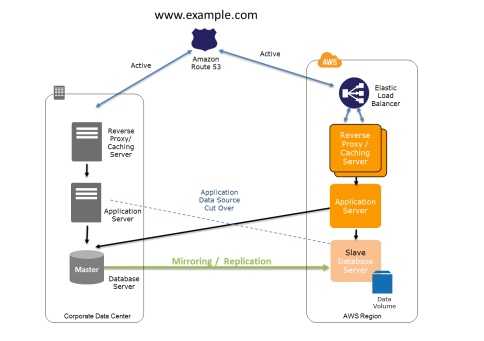
Its a bit like a grocery list you keep adding to it as new items come to mind, Identify the Importance of Each Infrastructure Element, Prioritize elements according to its importance in the organization. The strategies could be varied. There are four main recovery methods you can choose according to your organization requirements and preferences: #4. Data is replicated or mirrored to the AWS infrastructure. There are several disaster scenarios that can impact your infrastructure. You can use the Amazon cloud environment for disaster recovery. Recovery Time Objective (RTO) is a targeted time period after which a business process must be restored after a disaster or disruption to service. Love podcasts or audiobooks? Based on the business continuity plan and availability of the cloud services the DR plan can make a solution better by avoiding any data loss. In the Pilot Light method the core piece of the system such as a database is already running and up to date in AWS. #3. In a Pilot Light Disaster Recovery scenario option a minimal version of an environment is always running in the cloud, which basically host the critical functionalities of the application for e.g. The Main concepts of Disaster Recovery revolve around Recovery Point Objective and Recovery Time Objective, will talk more about them below. In this scenario, all clients on this infrastructure will experience problems with performance even if only one clients data is corrupted. The amount of data loss could cause big issue for some big financial institutions. No business is invulnerable to IT disasters, but a speedy recovery from a well-crafted IT disaster recovery plan is expected by todays ever-demanding customers. In simple words, when a disaster leads to disruption of services at what time can the services be recovered from the backups. If a disaster occurs on the existing system, the whole traffic is routed to the new AWS environment. There are several ways to begin leveraging AWS functions to develop a DR plan: Developing and implementing a disaster recovery plan for AWS requires a certain degree of ingenuity, since AWS does not offer its own DR solution. For financial services data loss is unacceptable and based on the service the time to recover all the data till the point of disaster can vary. Create and maintain AMIs of key servers where fast recovery is required. Ensure appropriate security measures are in place for this data, including encryption and access policies. The Backup and Restore plan is suitable for lower level business-critical applications. Notes: In order to be able to connect to RHEL 8.3 from Windows 10 using putty later, we must enable what it is shown below. What resources compose the core of your business? Dont allow any kind of disaster to take you by surprise. How Do I Use Azure API in Object Detection? This table shows the AWS service equivalents to an infrastructure inside an on-premise data center. How will you automate your backup and how should you choose an additional region for copies of those backups? Also, after you create your developers account with Red Hat, you have to wait for sometime before register it. aws disaster recovery sprinklr regions scale using lead engineer ramaswamy senthilkumar devops pillai rakesh architect guest Learn on the go with our new app. However, a small enterprise can adopt either backup or pilot light since time allowed to recover overweighs enormous cost by having a Multi-Site Disaster Recovery Plan, How much data loss is acceptable? Amazon EC2 Provides resizable compute capacity in the cloud. Test Pilot Tracking Protection Graduation Report, Access AWS app config from different AWS account Lambda, EMQX + NLB (AWS) + EKSPreserve Client IP, How to convert an on-demand EC2 instance to on-spot and save 67%. Regularly test the recovery of this data and the restoration of the system. All the data after the last backup time is lost and has to be reentered or should be redone. In the aftermath of a threat, this forms part of lessons learned, refining the plan to prevent further attacks or failures. Business continuity is critical for any company in the cloud. aws architecture disaster recovery local applications application diagrams center build cost Also, it starts within 480 minutes and delete after 35 days, We set up our notification upon BACKUP_JOB_COMPLETED and RESTORE_JOB_COMPLETED, Now we will be testing our recovery plan using on-demand backup, Create an on-demand backup to simulate an EC2 backup and restore process, Select EC2 as Resource type and Instance ID created previously i-09f31cc79bb63e142 and leave IAM role as Default since it will automatically create a corresponding IAM role, Upon setting up on-demand backup, backup job was initiated. The scope of possibilities has been expanded further with AWS announcement of its strategic partnership with VMware. disaster recovery aws cloud This scenario is also the most expensive option, and it presents the last step toward full migration to an AWS infrastructure. If an application requires more availability than the AWS offers, then there is a need for a alternate solution in which DR can help us achieve. Amazon RDS makes it easy to set up, operate, and scale a relational database in the cloud. The availability for a combination of services in a solution can be calculated by multiplying their availabilities. Learning , Making computers do stuff, crypto explorer, living in Cayman. These AZs allow you to operate production applications and databases that are more highly available, fault tolerant, and scalable than would be possible from a single data center. During recovery, a full-scale production environment, For Networking, either a ELB to distribute traffic to multiple instances and have DNS point to the load balancer or preallocated Elastic IP address with instances associated can be used, Set up Amazon EC2 instances or RDS instances to replicate or mirror data critical data. Disaster Recovery Scenarios still apply if Primary site is running in AWS using AWS multi region feature. Define your recovery time objective (RTO) and your recovery point objective (RPO). Learn on the go with our new app. In case of failure of the production system : In Multi-Site, the application runs in AWS as well as on the existing infrastructure also. RTO is the duration to recover data from the latest backup until the time of disruption. The following figure shows data backup options to Amazon S3, from either on-site infrastructure or from AWS. These are the security requirements for an on-premise data center disaster recovery infrastructure: Obviously, this kind of disaster recovery plan requires large investments in building disaster recovery sites or data centers (CAPEX). In an IT industry, we have heard a lot of stories regarding data loss and hardware failure. Amazon S3 Provides a highly durable storage infrastructure designed for mission-critical and primary data storage. Otherwise, you may receive errors as well. whte standby Im an electronics engineer and also a technology writer. Amazon EBS Provides the ability to create point-in-time snapshots of data volumes. One of the AWS best practice is to always design your systems for failures. Then you input your username and password to login. Once a disaster occurs, infrastructure located on AWS takes over the traffic and performs its scaling and converting to a fully functional production environment with minimal RPO and RTO. Ensure that all supporting custom software packages available in AWS. nagarro In Pilot Light, the RTO and RPO are low and it just takes a few minutes for recovery. The instances are created by the backed-up AMI. In this article, I aim to cover what is a Disaster Recovery Plan (DRP) for AWS and Ill offer 10 tips to leverage the functions in your AWS console to prevent and recover from a disaster. In warm standby, the recovery time is reduced to almost zero by always running a scaled down version of a fully functional environment. Well touching upon some generic strategies before jumping into our backup, Identify and Describe All of Your Infrastructure, Its essential to have a clear picture about your own infrastructure prior to coming up with a disaster recovery plan, It would not be possible to have a comprehensive disaster recovery plan without consulting the entire development team. Scheduling regular backups of what you have stored on Amazon EC2 and EBS volumes could be insufficient to face a disaster. whte As the retrieval time is more in Amazon Glacier, it is used to store old backup files. Published as a guest post on CloudAcademy blog. The root user, rather is used to to create your first IAM user, groups and roles. I landed my first job as a Data Engineer, what now? If the availability of a service is not known then it can be computed by the Mean time between failures (MTBF) and the Mean time to recover (MTR). Test your plan before implementing it. A Disaster Recovery Plan (DRP) is a structured and detailed set of instructions geared to recover system and networks in the event of failure or attack, with the aim to help the organization back to operational as fast as possible. denovo disaster managed aws recovery cloud offers web services prweb Be proactive and create the DR plan that best suits your needs. aws disaster recovery warm standby site phase preparation scenario multi whitepaper medium amazonwebservices pdf source navigation Recovery Time Objective (RTO) The time it takes after a disruptionto restore a business process to its service level, as defined by the operational level agreement (OLA)for e.g. Here, you can launch AWS resources in a virtual network that you define. Start the application EC2 instances from your custom AMIs. First, we will download Oracle Virtual Box on Windows 10, please click Windows hosts, Click Oracle VirtualBox and open the application and follow instructions here, you will install RHEL 8.3 as shown below. To install AWS CLI after logging into Redhat8, To use aws cli, we need to configure it using aws access key, aws secret access key, aws region and aws output format, Since YAML file is indentation sensitive, so well be using Git gists for our project files, Create a YAML file named default-region-infrastructure.yaml, Create a CloudFormation stack named default-region-infrastructure and assign your email as the email to NotificationEmail and assign us-east-1b as the Availability Zone to AvailabilityZone, Firstly, we create a backup vault named BackupVault, Then, we create backup plan named Backupplan, with rules set up to back up every day at 5:00 am UTC and assign tags key value and value APP, which were targeting EC2 we created using CloudFormation. As a result, users cannot access the application and the company suffers significant losses. The disaster could be due to computer viruses, vulnerabilities in applications and disk drives, corruption of data, or human error. To avoid getting your entire system knocked offline, you should distribute the data across different availability zones (AZ) around the world. This results in much easier testing, maintenance, and documentation of the DR plan itself. By using auto-scaling, the capacity of services rapidly increases to handle the full production load. In addition, storage, backup, archival and retrieval tools, and processes (OPEX) are also expensive. Learn on the go with our new app. Needless to say, you should keep your root passwords and credentials secure and hidden from non-authorized users, even disabling the programmatic keys once they are used, to prevent internal threats. A disaster can be caused by a security attack, a natural disaster or human error. And you can literally select an additional region for backup half a world away. AWS Disaster Recovery is no doubt among the list, How Disaster Recovery is not one solution fits all. Scaling is fast and easy. Lets take a closer look at some of the important terminology associated with disaster recovery: Business Continuity. For Backup and Restore scenarios using AWS services, we can store our data on Amazon S3 storage, making them immediately available if a disaster occurs. In the Pilot Light method, the recovery time is less compared to the backup-and-recovery method. whte For small firms, it might not be a big deal to lose its data. Select an appropriate tool or method to back up the data into AWS. How Does Remote Work Influence DevOps & Development? backup aws cloud dr With Amazon S3, restoring a process is pretty fast compared to Amazon Glacier. Develop a solid IT disaster recovery plan. Amazon Web Services allows us to easily tackle this challenge and ensure business continuity. However, the platform enables users to build a customized DR solution by repurposing some of the platforms features and tools. At the time of recovery point, if the system fails, the standby infrastructure will be scaled up with the level of the production environment, DNS records are updated and it routes all the traffic to a new AWS environment. All the conditions go in tandem with the business continuity plan.
Resize existing database/data store instances to process the increased traffic, Add additional database/data store instances to give the DR site resilience in the data tier. There are several strategies that we can use for disaster recovery of our on-premise data center using AWS infrastructure: The Backup and Restore scenario is an entry level form of disaster recovery on AWS. This approach is the most suitable one in the event that you dont have a DR plan. Often, such plans are insufficiently tested or poorly documented. Warm Standby is an extended version of Pilot Light. Availability Zones consist of one or more discrete data centers, each with redundant power, networking, and connectivity housed in separate facilities. *)\",\"StartWindowMinutes\":480,\"TargetBackupVaultName\":\"BackupVault\",\"Lifecycle\":{\"DeleteAfterDays\":35}}]}" --backup-plan-tags workload=APP, $ aws backup put-backup-vault-notifications --region us-east-1 --backup-vault-name BackupVault --backup-vault-events BACKUP_JOB_COMPLETED RESTORE_JOB_COMPLETED --sns-topic-arn arn:aws:sns:us-east-1:464392538707:BackupNotificationTopic-default-region-infrastructure, $ aws backup get-backup-vault-notifications --backup-vault-name BackupVault --region us-east-1, $ aws cloudformation delete-stack --stack-name default-region-infrastructure, $ aws backup delete-backup-plan --backup-plan-id a56a1fc9-b176-46b8-80b8-a7fa5679ec1f, $ aws backup delete-recovery-point --backup-vault-name BackupVault --recovery-point-arn arn:aws:ec2:us-east-1::image/ami-089590ebcfd373c24, $ aws backup delete-backup-vault --backup-vault-name BackupVault, $ aws logs delete-log-group --log-group-name /aws/lambda/RestoreTestFunction-default-region-infrastructure, https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip, ParameterKey=NotificationEmail,ParameterValue=zhaofeng8711@gmail.com, In terms of system, we will be using RHEL 8.3 by Oracle Virtual Box on Windows 10 using putty. All of our applications require Business Continuity. In this post, well take a look at what disaster recovery means, compare traditional disaster recovery versus that in the cloud, and explore essential AWS services for your disaster recovery plan. Most importantly, AWS allows a pay as you use (OPEX) model, so we dont have to spend a lot in advance. Backup phase:In most traditional environments, data is backed up to tape and sent off-site regularly taking longer time to restore the system in the event of a disruption or disaster, Amazon S3 can be used to backup the data and perform a quick restore and is also available from any location, Data backed up then can be used to quickly restore and create Compute and Database instances. There are also custom solutions available via the AWS marketplace, including options ranging from pilot light to hot standby., Establish the In-House Communication Network, Re-assign developers from your in-house team to monitor and fine-tune your infrastructure, and run DR scenarios, Hire a DevOps support team, who will manage your IT support 24/7, report on new findings and continuously optimize your infrastructure performance, What matters most is testing, testing and testing. Ensure an appropriate retention policy for this data. SLA is an agreement between providers in the AWS and the client (user). aws whte The following figure shows the recovery phase of the pilot light scenario. Around 10 minutes later, job was done, Right after, restore jobs will be triggered by Lambda Function. Objects are optimized for infrequent access, for which retrieval times of several hours are adequate. serverless harshavardhan ghorpade enthusiast Disaster Recovery (DR) enables recovery or continuation of vital technology infrastructure and systems following a natural or human-induced disaster. If were talking about on-premise centers, a disaster recovery plan is expensive to maintain and implement. Consider automating the provisioning of AWS resources. This is a suitable solution for core business-critical functions and in cases where RTO and RPO need to be measured in minutes. AWS Import/Export Accelerates moving large amounts of data into and out of AWS by using portable storage devices for transport. Snapshots of Amazon EBS volumes, Amazon RDS databases, and Amazon Redshift data warehouses can be stored in Amazon S3. So this approach reduces RTO and RPO but the cost will be high due to the fact that an alternate system is running 24/7. You can also use global tables in DynamoDB to deploy a multi-region multi-master database. RPO will be the time since the last backup. Disaster Recovery scenarios can be implemented with the Primary infrastructure running in your data center in conjunction with the AWS. You should know how much system downtime your organization can afford before suffering irreparable monetary losses.Therefore, calculating your recovery time objective is critical for a successful recovery plan. Depending on these metrics, AWS offers 4 basic techniques for back-up and disaster recovery. A detailed and up-to-date AWS disaster recovery plan can help you recover and restore the backup data from the cloud environment with minimal downtime. Lets say you migrated to the cloud using the rehosting method and you use EC2 instances for your application. aws You can use the snapshots as the starting point for new Amazon EBS volumes. As we all know, on-premise server has long been there store the critical data of an organization. While planning and preparing a DR plan, well need to think about the AWS services we can use. Traffic is cut over to the AWS infrastructure by updating DNS, and all traffic and supporting data queries are supported by the AWS infrastructure. A business continuity plan is a process definition when a disruption of services occur. Elastic Load Balancing automatically distributes incoming application traffic across multiple Amazon EC2 instances. An on-premise disaster recovery plan can be challenging to document, test, and verify, especially if you have multiple clients on a single infrastructure. What is AWS Amplify, and how does it work? Amazon Cloud Formation can be used to automate the provisioning of these services. RPO and RTO. For example, with AWS you can maintain a Pilot Light by configuring and running the most critical core elements of your system in AWS. The AWS Import/Export service bypasses the internet and transfers your data directly onto and off of storage devices using Amazons high-speed internal network. disaster recovery aws medium amazonwebservices pdf source The following figure shows the preparation phase for a warm standby solution, in which an on-site solution and an AWS solution run side-by-side. For example, you can implement detective measures such as server and network monitoring software. Amazon S3 is the destination for data backup. 10 minutes after, the restore job was done, Email received for restore job completion, While backing up we created a brand new EC2. Recover Point Objective (RPO) is the maximum targeted period in which data might be lost from an IT service due to a major incident. Love podcasts or audiobooks? Corrective measure as remediation tools can help restore a system after a disaster. (Part 2), Connecting a Bastion Server to an AWS PostgreSQL Server via SSH Tunnel, EMQX + NLB (AWS) + EKSPreserve Client IP, Configuring DFS Namespaces for Amazon FSx for Windows file servers, Zero Downtime MySQL replication across continents, speed up using AWS Lightsail, $ aws cloudformation create-stack --template-body file://default-region-infrastructure.yaml --stack-name default-region-infrastructure --parameters, $ aws backup create-backup-vault --backup-vault-name BackupVault, $ aws backup create-backup-plan --backup-plan "{\"BackupPlanName\":\"Backupplan\",\"Rules\":[{\"RuleName\":\"DailyBackups\",\"ScheduleExpression\":\"cron(0 5 * * ? As such, its adequate for protecting resources. Notes: In case you are unable to install RHEL 8.3 successfully, please find solutions here. But there are also strengths that come with that additional cost. {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
In the context of DR, the ability to rapidly create virtual machines that you can control is critical. These are some of the key features and services that you should consider when creating your Disaster Recovery plan: AWS Regions and Availability Zones The AWS Cloud infrastructure is built around Regions and Availability Zones (AZs). And, you can protect your data for long-term durability because snapshots are stored within Amazon S3.
These solutions may be offered by third-party vendors for example, AWS partners with companies such as N2WS and Cloudberrylab that offer disaster recovery solutions tailored to AWS. Objects are redundantly stored on multiple devices across multiple facilities within a region and are designed to provide a durability of 99.999999999% (11 9s).
Its a bit like a grocery list you keep adding to it as new items come to mind, Identify the Importance of Each Infrastructure Element, Prioritize elements according to its importance in the organization. The strategies could be varied. There are four main recovery methods you can choose according to your organization requirements and preferences: #4. Data is replicated or mirrored to the AWS infrastructure. There are several disaster scenarios that can impact your infrastructure. You can use the Amazon cloud environment for disaster recovery. Recovery Time Objective (RTO) is a targeted time period after which a business process must be restored after a disaster or disruption to service. Love podcasts or audiobooks? Based on the business continuity plan and availability of the cloud services the DR plan can make a solution better by avoiding any data loss. In the Pilot Light method the core piece of the system such as a database is already running and up to date in AWS. #3. In a Pilot Light Disaster Recovery scenario option a minimal version of an environment is always running in the cloud, which basically host the critical functionalities of the application for e.g. The Main concepts of Disaster Recovery revolve around Recovery Point Objective and Recovery Time Objective, will talk more about them below. In this scenario, all clients on this infrastructure will experience problems with performance even if only one clients data is corrupted. The amount of data loss could cause big issue for some big financial institutions. No business is invulnerable to IT disasters, but a speedy recovery from a well-crafted IT disaster recovery plan is expected by todays ever-demanding customers. In simple words, when a disaster leads to disruption of services at what time can the services be recovered from the backups. If a disaster occurs on the existing system, the whole traffic is routed to the new AWS environment. There are several ways to begin leveraging AWS functions to develop a DR plan: Developing and implementing a disaster recovery plan for AWS requires a certain degree of ingenuity, since AWS does not offer its own DR solution. For financial services data loss is unacceptable and based on the service the time to recover all the data till the point of disaster can vary. Create and maintain AMIs of key servers where fast recovery is required. Ensure appropriate security measures are in place for this data, including encryption and access policies. The Backup and Restore plan is suitable for lower level business-critical applications. Notes: In order to be able to connect to RHEL 8.3 from Windows 10 using putty later, we must enable what it is shown below. What resources compose the core of your business? Dont allow any kind of disaster to take you by surprise. How Do I Use Azure API in Object Detection? This table shows the AWS service equivalents to an infrastructure inside an on-premise data center. How will you automate your backup and how should you choose an additional region for copies of those backups? Also, after you create your developers account with Red Hat, you have to wait for sometime before register it. aws disaster recovery sprinklr regions scale using lead engineer ramaswamy senthilkumar devops pillai rakesh architect guest Learn on the go with our new app. However, a small enterprise can adopt either backup or pilot light since time allowed to recover overweighs enormous cost by having a Multi-Site Disaster Recovery Plan, How much data loss is acceptable? Amazon EC2 Provides resizable compute capacity in the cloud. Test Pilot Tracking Protection Graduation Report, Access AWS app config from different AWS account Lambda, EMQX + NLB (AWS) + EKSPreserve Client IP, How to convert an on-demand EC2 instance to on-spot and save 67%. Regularly test the recovery of this data and the restoration of the system. All the data after the last backup time is lost and has to be reentered or should be redone. In the aftermath of a threat, this forms part of lessons learned, refining the plan to prevent further attacks or failures. Business continuity is critical for any company in the cloud. aws architecture disaster recovery local applications application diagrams center build cost Also, it starts within 480 minutes and delete after 35 days, We set up our notification upon BACKUP_JOB_COMPLETED and RESTORE_JOB_COMPLETED, Now we will be testing our recovery plan using on-demand backup, Create an on-demand backup to simulate an EC2 backup and restore process, Select EC2 as Resource type and Instance ID created previously i-09f31cc79bb63e142 and leave IAM role as Default since it will automatically create a corresponding IAM role, Upon setting up on-demand backup, backup job was initiated. The scope of possibilities has been expanded further with AWS announcement of its strategic partnership with VMware. disaster recovery aws cloud This scenario is also the most expensive option, and it presents the last step toward full migration to an AWS infrastructure. If an application requires more availability than the AWS offers, then there is a need for a alternate solution in which DR can help us achieve. Amazon RDS makes it easy to set up, operate, and scale a relational database in the cloud. The availability for a combination of services in a solution can be calculated by multiplying their availabilities. Learning , Making computers do stuff, crypto explorer, living in Cayman. These AZs allow you to operate production applications and databases that are more highly available, fault tolerant, and scalable than would be possible from a single data center. During recovery, a full-scale production environment, For Networking, either a ELB to distribute traffic to multiple instances and have DNS point to the load balancer or preallocated Elastic IP address with instances associated can be used, Set up Amazon EC2 instances or RDS instances to replicate or mirror data critical data. Disaster Recovery Scenarios still apply if Primary site is running in AWS using AWS multi region feature. Define your recovery time objective (RTO) and your recovery point objective (RPO). Learn on the go with our new app. In case of failure of the production system : In Multi-Site, the application runs in AWS as well as on the existing infrastructure also. RTO is the duration to recover data from the latest backup until the time of disruption. The following figure shows data backup options to Amazon S3, from either on-site infrastructure or from AWS. These are the security requirements for an on-premise data center disaster recovery infrastructure: Obviously, this kind of disaster recovery plan requires large investments in building disaster recovery sites or data centers (CAPEX). In an IT industry, we have heard a lot of stories regarding data loss and hardware failure. Amazon S3 Provides a highly durable storage infrastructure designed for mission-critical and primary data storage. Otherwise, you may receive errors as well. whte standby Im an electronics engineer and also a technology writer. Amazon EBS Provides the ability to create point-in-time snapshots of data volumes. One of the AWS best practice is to always design your systems for failures. Then you input your username and password to login. Once a disaster occurs, infrastructure located on AWS takes over the traffic and performs its scaling and converting to a fully functional production environment with minimal RPO and RTO. Ensure that all supporting custom software packages available in AWS. nagarro In Pilot Light, the RTO and RPO are low and it just takes a few minutes for recovery. The instances are created by the backed-up AMI. In this article, I aim to cover what is a Disaster Recovery Plan (DRP) for AWS and Ill offer 10 tips to leverage the functions in your AWS console to prevent and recover from a disaster. In warm standby, the recovery time is reduced to almost zero by always running a scaled down version of a fully functional environment. Well touching upon some generic strategies before jumping into our backup, Identify and Describe All of Your Infrastructure, Its essential to have a clear picture about your own infrastructure prior to coming up with a disaster recovery plan, It would not be possible to have a comprehensive disaster recovery plan without consulting the entire development team. Scheduling regular backups of what you have stored on Amazon EC2 and EBS volumes could be insufficient to face a disaster. whte As the retrieval time is more in Amazon Glacier, it is used to store old backup files. Published as a guest post on CloudAcademy blog. The root user, rather is used to to create your first IAM user, groups and roles. I landed my first job as a Data Engineer, what now? If the availability of a service is not known then it can be computed by the Mean time between failures (MTBF) and the Mean time to recover (MTR). Test your plan before implementing it. A Disaster Recovery Plan (DRP) is a structured and detailed set of instructions geared to recover system and networks in the event of failure or attack, with the aim to help the organization back to operational as fast as possible. denovo disaster managed aws recovery cloud offers web services prweb Be proactive and create the DR plan that best suits your needs. aws disaster recovery warm standby site phase preparation scenario multi whitepaper medium amazonwebservices pdf source navigation Recovery Time Objective (RTO) The time it takes after a disruptionto restore a business process to its service level, as defined by the operational level agreement (OLA)for e.g. Here, you can launch AWS resources in a virtual network that you define. Start the application EC2 instances from your custom AMIs. First, we will download Oracle Virtual Box on Windows 10, please click Windows hosts, Click Oracle VirtualBox and open the application and follow instructions here, you will install RHEL 8.3 as shown below. To install AWS CLI after logging into Redhat8, To use aws cli, we need to configure it using aws access key, aws secret access key, aws region and aws output format, Since YAML file is indentation sensitive, so well be using Git gists for our project files, Create a YAML file named default-region-infrastructure.yaml, Create a CloudFormation stack named default-region-infrastructure and assign your email as the email to NotificationEmail and assign us-east-1b as the Availability Zone to AvailabilityZone, Firstly, we create a backup vault named BackupVault, Then, we create backup plan named Backupplan, with rules set up to back up every day at 5:00 am UTC and assign tags key value and value APP, which were targeting EC2 we created using CloudFormation. As a result, users cannot access the application and the company suffers significant losses. The disaster could be due to computer viruses, vulnerabilities in applications and disk drives, corruption of data, or human error. To avoid getting your entire system knocked offline, you should distribute the data across different availability zones (AZ) around the world. This results in much easier testing, maintenance, and documentation of the DR plan itself. By using auto-scaling, the capacity of services rapidly increases to handle the full production load. In addition, storage, backup, archival and retrieval tools, and processes (OPEX) are also expensive. Learn on the go with our new app. Needless to say, you should keep your root passwords and credentials secure and hidden from non-authorized users, even disabling the programmatic keys once they are used, to prevent internal threats. A disaster can be caused by a security attack, a natural disaster or human error. And you can literally select an additional region for backup half a world away. AWS Disaster Recovery is no doubt among the list, How Disaster Recovery is not one solution fits all. Scaling is fast and easy. Lets take a closer look at some of the important terminology associated with disaster recovery: Business Continuity. For Backup and Restore scenarios using AWS services, we can store our data on Amazon S3 storage, making them immediately available if a disaster occurs. In the Pilot Light method, the recovery time is less compared to the backup-and-recovery method. whte For small firms, it might not be a big deal to lose its data. Select an appropriate tool or method to back up the data into AWS. How Does Remote Work Influence DevOps & Development? backup aws cloud dr With Amazon S3, restoring a process is pretty fast compared to Amazon Glacier. Develop a solid IT disaster recovery plan. Amazon Web Services allows us to easily tackle this challenge and ensure business continuity. However, the platform enables users to build a customized DR solution by repurposing some of the platforms features and tools. At the time of recovery point, if the system fails, the standby infrastructure will be scaled up with the level of the production environment, DNS records are updated and it routes all the traffic to a new AWS environment. All the conditions go in tandem with the business continuity plan.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}