The following Kafka Streams transformation examples are primarily examples of stateless transformations. #flatMap(KeyValueMapper)). Instant access to millions of ebooks, audiobooks, magazines, podcasts and more. This is a stateful record-by-record operation, i.e, transform(Object, Object) is invoked individually for each record of a stream and can access and modify  An additional changelog topic and a persistent KeyValue store meant more storage overhead on top of the repartition topic and slower startup times for the application as well since they had to read from this topic. and we tested the expected results for filters on sensor-1 and sensor-2 and a default. If the key is already known, the only thing we do is merge the new value with the existing one we have. Enjoy access to millions of ebooks, audiobooks, magazines, and more from Scribd.
An additional changelog topic and a persistent KeyValue store meant more storage overhead on top of the repartition topic and slower startup times for the application as well since they had to read from this topic. and we tested the expected results for filters on sensor-1 and sensor-2 and a default. If the key is already known, the only thing we do is merge the new value with the existing one we have. Enjoy access to millions of ebooks, audiobooks, magazines, and more from Scribd.  kafka stream processing javatpoint processors topology present major following there We need to simply call this function in our transform method right after the loop is done: You are probably wondering why transform returns null. APIdays Paris 2019 - Innovation @ scale, APIs as Digital Factories' New Machi Mammalian Brain Chemistry Explains Everything. I was deciding how and what goes to internal topic(s), and I had better control over my data overall. Kafka Stream Transformations are available from `KTable` or `KStream` and will result in one or more `KTable`, `KStream` or `KGroupedTable` depending on the transformation function. We are using a UUID as the primary key, which normally avoids this kind of lock contention since the distribution of new keys is pretty random across the index. We also need a map holding the value associated with each key (a KeyValueStore). A state store instance is created per partition and can be either persistent or in-memory only. This is For example, lets imagine you wish to filter a stream for all keys starting with a particular string in a stream processor. text in a paragraph. &stream-builder-${stream-listener-method-name} : More about this at https://cloud.spring.io/spring-cloud-static/spring-cloud-stream-binder-kafka/2.2.0.RC1/spring-cloud-stream-binder-kafka.html#_accessing_the_underlying_kafkastreams_object, Line 2: Get actual StreamBuilder from our factory bean, Line 3: Create StoreBuilder that builds KeyValueStore with String serde defined for its key, and Long serde defined for its value, Line 4: Add our newly created StoreBuilder to StreamBuilder. Sometimes the same activity receives updates seconds apart as our staff and suppliers make their changes. It has its pros and cons. This is great for reliability since our transformer can pick up right where it left off if our service crashes. Our first solution used Kafka Streams DSL groupByKey() and reduce() operators, with the aggregation being performed on fixed interval time windows. To populate the outbox table, we created a Hibernate event listener that notes which relevant entities got modified in the current transaction. To trigger periodic actions via We can do so as the aggregation results don't have to be persisted after they have been forwarded. Ill explain what we are doing line by line: Line 1: Get StreamBuilderFactoryBean using ApplicationContext based by a name. The challenges we faced with a time-based windowing and groupByKey() + reduce() approach indicated that it was not the most ideal approach for our use case. But, lets get started. Here we simply create a new key, value pair with the same key, but an updated value.
kafka stream processing javatpoint processors topology present major following there We need to simply call this function in our transform method right after the loop is done: You are probably wondering why transform returns null. APIdays Paris 2019 - Innovation @ scale, APIs as Digital Factories' New Machi Mammalian Brain Chemistry Explains Everything. I was deciding how and what goes to internal topic(s), and I had better control over my data overall. Kafka Stream Transformations are available from `KTable` or `KStream` and will result in one or more `KTable`, `KStream` or `KGroupedTable` depending on the transformation function. We are using a UUID as the primary key, which normally avoids this kind of lock contention since the distribution of new keys is pretty random across the index. We also need a map holding the value associated with each key (a KeyValueStore). A state store instance is created per partition and can be either persistent or in-memory only. This is For example, lets imagine you wish to filter a stream for all keys starting with a particular string in a stream processor. text in a paragraph. &stream-builder-${stream-listener-method-name} : More about this at https://cloud.spring.io/spring-cloud-static/spring-cloud-stream-binder-kafka/2.2.0.RC1/spring-cloud-stream-binder-kafka.html#_accessing_the_underlying_kafkastreams_object, Line 2: Get actual StreamBuilder from our factory bean, Line 3: Create StoreBuilder that builds KeyValueStore with String serde defined for its key, and Long serde defined for its value, Line 4: Add our newly created StoreBuilder to StreamBuilder. Sometimes the same activity receives updates seconds apart as our staff and suppliers make their changes. It has its pros and cons. This is great for reliability since our transformer can pick up right where it left off if our service crashes. Our first solution used Kafka Streams DSL groupByKey() and reduce() operators, with the aggregation being performed on fixed interval time windows. To populate the outbox table, we created a Hibernate event listener that notes which relevant entities got modified in the current transaction. To trigger periodic actions via We can do so as the aggregation results don't have to be persisted after they have been forwarded. Ill explain what we are doing line by line: Line 1: Get StreamBuilderFactoryBean using ApplicationContext based by a name. The challenges we faced with a time-based windowing and groupByKey() + reduce() approach indicated that it was not the most ideal approach for our use case. But, lets get started. Here we simply create a new key, value pair with the same key, but an updated value.
Furthermore, via It then uses Spring's TransactionSynchronization facility to trigger corresponding inserts to the outbox table right before a transaction is committed. Developers refer to the processor API when Apache Kafka Streams toolbox doesnt have a right tool for their needs OR they need better control over their data. This overhead meant that messages already having higher payload size, would leave an even higher footprint on the Kafka broker. RabbitMQ with fanout processing). The outbox pattern is a good fit for this task. Transforming records might result in an internal data redistribution if a key based operator (like an aggregation instance. We also want to test it, right? Call initializeStateStores method from our requestListener : We need to initialize our CustomProcessor in KStream .
How did we move the mountain? This should be pretty simple. Github: https://github.com/yeralin/custom-kafka-streams-transformer-demo. VWO Session Recordings capture all visitor interaction with a website, and the payload size of the Kafka messages is significantly higher than our other applications that use Kafka. Marks the stream for data re-partitioning: we are using both `flatMap` from Kafka Streams as well as `flatMap` from Scala. Were going to cover examples in Scala, but I think the code would readable and comprehensible for those of you with a Java preference as well. can be altered arbitrarily). This kind of buffering and deduplication is not always trivial to implement when using job queues. 1. Otherwise, it will throw something along the lines with: Ooof. Lets add another method called findAndFlushCandidates: When we call findAndFlushCandidates , it will iterate over our state store, check if the cap for a pair is reached, flush the pair using this.context.forward(key, value) call, and delete the pair from the state store. Today, we will implement a stateful transformer, so we could utilize as much available features as possible. The Adaptive MACDCoding Technical Indicators. Your email address will not be published. the original values an, Transform each record of the input stream into a new record in the output stream Well, I didnt tell you a whole story. join with default ser, A Java virtual machine. Nevertheless, with an application having nearly the same architecture in production working well, we began working on a solution. To perform aggregation based on customerId, Our expectation of window-based aggregation was that for each key we would receive the results in the downstream Processor nodes strictly after the expiration of the window. In this Kafka Streams Transformations tutorial, the `branch` example had three predicates: two filters for key name and one default predicate for everything else.
stream kafka apache processing dzone api topology processor Instead of writing to a job queue for every request that updates the database, we insert an entry into another database table (called outbox) which contains a description of additional work that needs to be done (i.e. Hope these examples helped. kafka processor Feel free to play around with the code, add more payloads, modify aggregation logic. For our use case we need two state stores. Surprisingly, it comes from the name of our method annotated with @StreamListener i.e. org.hibernate.type.descriptor.java.BlobTypeDescriptor, org.hibernate.jpamodelgen.xml.jaxb.AccessType, org.hibernate.resource.beans.container.spi.ContainedBean, org.hibernate.cfg.annotations.reflection.XMLContext.Default, org.hibernate.resource.beans.container.spi.BeanContainer, org.hibernate.resource.beans.spi.BeanInstanceProducer, org.hibernate.type.descriptor.java.LocaleTypeDescriptor, org.hibernate.mapping.PersistentClassVisitor, org.hibernate.type.descriptor.sql.JdbcTypeFamilyInformation, org.springframework.messaging.rsocket.MetadataExtractor, Javatips.net provides unique and complete articles about Visitor Java class represents the input Kafka message and has JSON representation : VisitorAggregated Java class is used to batch the updates and has the JSON representation : The snippet below describes the code for the approach. Make it shine! The topic names, Group the records by their current key into a KGroupedStream while preserving Define following properties under application.properties : Should be pretty self-descriptive, but let me explain the main parts: Lets enable binding and create a simple stream listener that would print incoming messages: So far, so good! You can flush key-value pairs in two ways: by using previously mentioned this.context.forward(key, value) call or by returning the pair in transform method. All rights reserved. It is a little tricky right now in Spring Framework (and I hope they improve it later, but here is what I came up with). The SlideShare family just got bigger. Here is the method that it calls: Now we instantiate the transformer and set up some Java beans in a configuration class using Spring Cloud Stream: The last step is to map these beans to input and output topics in a Spring properties file: We then scope this configuration class and properties to a specific Spring profile (same for the Kafka consumer), corresponding to a deployment which is separate from the one that serves web requests. In the tests, we test for the new values from the result stream. SlideShare uses cookies to improve functionality and performance, and to provide you with relevant advertising. In Kafka Streams, these are called state stores and are actually Kafka topics themselves. Kafka Streams Take on Watermarks and Triggers, Programmatic Authentication under IAP on GCP. kafka streams semantics join the given predicate. Lets create a class CustomProcessor that will implement a Transformer where K and V are your input key-value entries, and R is a result of your transformer. Stateful transformations, on the other hand, perform a round-trip to kafka broker(s) to persist data transformations as they flow. It will be beneficial to both, people who work with Kafka Streams, and people who are integrating Kafka Streams with their Spring applications. Personally, I got to the processor API when I needed a custom count based aggregation. We check whether its key is present in our queue. Culture & PeopleCustomer ServiceData Science Diversity & InclusionEngineering ManagementEventsFinance & LegalLeadershipMarketingProduct & DesignRecruiting & Talent DevelopmentRelocation 101Sales & SupplyTech & EngineeringWorking at GetYourGuide. Since stream building is happening under Springs hood, we need to intercept it in order to create our state store: 2. Apache Kafka from 0.7 to 1.0, History and Lesson Learned. And I really liked the processor API! With an empty table, MySQL effectively locks the entire index, so every concurrent transaction has to wait for that lock.We got rid of this kind of locking by lowering the transaction isolation level from MySQL's default of REPEATABLE READ to READ COMMITTED. The Transformer interface is for stateful mapping of an input record to zero, one, or multiple new output records (both key and value type can be altered arbitrarily). Clipping is a handy way to collect important slides you want to go back to later. Your email address will not be published. kafka microservices dobraemerytura computingforgeeks Transform each record of the input stream into zero or more records in the output stream (both key and value type Hello, today Im going to talk about this pretty complex topic of Apache Kafka Streams Processor API (https://docs.confluent.io/current/streams/developer-guide/processor-api.html). Notice in the test class we are passing two records with the value of MN now. In this example, we use the passed in filter based on values in the KStream. Kafka Streams Transformation Examples featured image:https://pixabay.com/en/dandelion-colorful-people-of-color-2817950/. This smaller, aggregated topic is what our service consumes instead to update the cache. Do let me know if you have any questions, comments or ideas for improvement. Enabling Insight to Support World-Class Supercomputing (Stefan Ceballos, Oak ksqlDB: A Stream-Relational Database System. We are using In-memory key-value stores for storing aggregation results and have turned off changelog topic-based backup of the state store. We should also implement a logic for reaching the cap and flushing the changes. After some research, we came across the Processor API. These are the dependencies we need (in Gradle's build.gradle format): Our transformer implements the Transformer interface from kafka-streams, which allows stateful transformation of records from one Kafka topic to another. Copyright Wingify. It is recommended to watch the short screencast above, before diving into the examples. From the Kafka Streams documentation, its important to note. You might also be interested in: Leveraging an event-driven architecture to build meaningful customer relationships. A The obvious approach of using a job queue would already give us this. The state store is a simple key-value store that uses RocksDB which also (by default) persists data in an internal kafka topic. #pr, Group the records of this KStream on a new key that is selected using the Activate your 30 day free trialto continue reading. Datetime formatting i, [], String> uppercasedAndAnonymized = input, , edgesGroupedBySource.queryableStoreName(), localworkSetStoreName). The way we wanted to batch updates to an external sink for a particular customer's data was to fire an update if either : The batching strategy we wanted to implement was similar to functionality frameworks like Apache Beam provide through the concept of windows and triggers. With few load test runs, we observed certain areas of concern. A brief overview of the above code snippet: In theory, all looked good, and an existing Kafka Streams application having nearly the same logic working well in production increased our confidence in this solution. The result of the aggregation step is a KTable object and is persisted and replicated for fault tolerance with a compacted Kafka changelog topic. See our User Agreement and Privacy Policy. kafka ksqldb SlideShare uses cookies to improve functionality and performance, and to provide you with relevant advertising. What we wanted to do for the recordings feature was quite similar. Transformer must return a The Transformer interface having access to a key-value store and being able to schedule tasks at fixed intervals meant we could implement our desired batching strategy. Or, a certain amount of time had elapsed since the last update. KStream. Building Large-Scale Stream Infrastructures Across Multiple Data Centers with Changing landscapes in data integration - Kafka Connect for near real-time da Real-time Data Ingestion from Kafka to ClickHouse with Deterministic Re-tries How Zillow Unlocked Kafka to 50 Teams in 8 months | Shahar Cizer Kobrinsky, Z Running Kafka On Kubernetes With Strimzi For Real-Time Streaming Applications. [Confluent] , Evolution from EDA to Data Mesh: Data in Motion. data is not sent (roundtriped)to any internal Kafka topic. Required fields are marked *. Lets define CommandLineRunner where we will initialize simple KafkaProducer and send some messages to our Kafka Streams listener: Then, if you start your application, you should see the following logs in your console: As expected, it aggregated and flushed characters b and c while a:6 is waiting in the state store for more messages. Because I can!). Understanding Salesforce Triggers and working with them, Spring Boot MicroservicesPart7Event Driven Using RabbitMQ, Distributed micro-services using Spring CloudAPI Gateway. When we return null in the method, nothing gets flushed.
If it isn't, we add the key along with a timestamp e.g.
kafka hive queries Ill try to post more interesting stuff Im working on. Recently, the team was tasked with providing up-to-date aggregations of catalog data to be used by the frontend of the GetYourGuide website. Check out our open positions. In case of a consumer rebalance, the new/existing Kafka Stream application instance reads all messages from this changelog topic and ensures it is caught up with all the stateful updates/computations an earlier consumer that was processing messages from those partitions made. Love podcasts or audiobooks? To maintain the current state of processing the input and outputs, Kafka Streams introduces a construct called a State Store. The filter` function can filter either a KTable or KStream to produce a new KTable or KStream respectively. databricks
The provided The number of events for that customer exceeded a certain threshold. kafka tutorial The other initialization step is to set up a periodic timer (called a punctuation in Kafka Streams) which will call a method of ours that scans the queue from the top and flushes out any records (using ProcessorContext#forward()) that are due to be forwarded, then removes them from the state stores. dataiku All of this happens independently of the request that modified the database, keeping those requests resilient. In order to make our CustomProcessor to work, we need to pre-create our state store. Transitioning Activision Data Pipeline to Streamin What's inside the black box? Thats why I also became a contributor to Kafka Streams to help other maintainers in advancing this amazing piece of software. Copyright 2011-2021 Javatips.net, all rights reserved. Schedule actions to occur at strictly regular intervals(wall-clock time) and gain full control over when records are forwarded to specific Processor Nodes. How to add headers using KStream API (Java). So, when we had to implement the VWO Session Recordings feature for the new Data platform, Kafka was a logical choice, with Kafka Streams framework doing all the heavy lifting involved with using Kafka Consumer API, allowing us to focus on the data processing part. Before we begin going through the Kafka Streams Transformation examples, Id recommend viewing the following short screencast where I demonstrate how to runthe Scala source code examples in IntelliJ. Stateless transformations do not require state for processing. If you continue browsing the site, you agree to the use of cookies on this website. kafka Pros: when you make a continuous transformation and your instance(s) goes down, other instance (or after a restart) will pick up the work where it got left off. It deserves a whole new article, also pretty complex and interesting topic. His team's mission is to develop the services that store our tours and activities' core data and further structure and improve the quality of that data. into zero or more value, Creates an array of KStream from this stream by branching the records in the Lets create a message binding interface: Then assuming that you have Kafka broker running under localhost:9092 . which cache entries need to be updated). Now you can start our application, send some messages, and you should see that the messages are being received by our Kafka Streams listener. In this case, you would need state to know what has been processed already in previous messages in the stream in order to keep a running tally of the sum result. But what about scalability? But wait! and have similarities to functional combinators found in languages such as Scala. To process the inserts to the outbox table, we use Debezium, which follows the MySQL binlog and writes any new entries to a Kafka topic. Stateless transformers dont leave any memory or network footprints on brokers side, the transformation happens on the client side i.e. ProcessorContext. Free access to premium services like Tuneln, Mubi and more. Below is the code snippet using the transform() operator. Instead of directly consuming the aforementioned Kafka topic coming from Debezium, we have a transformer consume this topic, hold the records in temporary data structures for a certain time while deduplicating them, and then flush them periodically to another Kafka topic. In software, the fastest implementation is one that performs no work at all, but the next best thing is to have the work performed ahead of time. 3. I also didnt like the fact that Kafka Streams would create many internal topics that I didnt really need and that were always empty (possibly happened due to my silliness).
Moreover, you can distribute (balance) the transformation work among instances to reduce the workload. A VirtualMachine represents a Java virtual machine to which this Java vir, A flow layout arranges components in a left-to-right flow, much like lines of
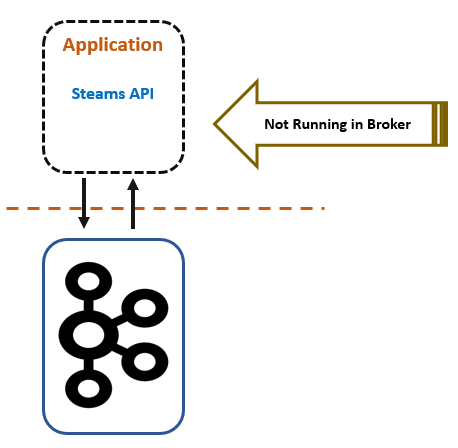
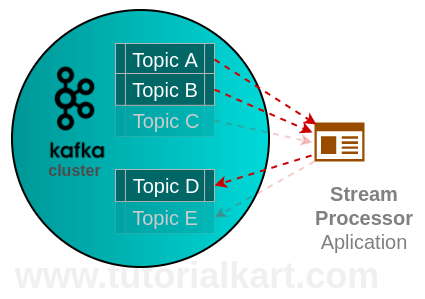
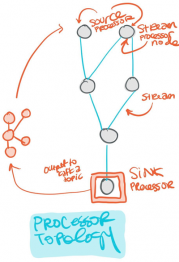
kafka rtd streams As previously mentioned, stateful transformations depend on maintainingthe state of the processing. With all these changes in place, our system is better decoupled and more resilient, all the while having an up-to-date caching mechanism that scales well and is easily tuned. You may also be interested in: How we built our modern ETL pipeline. Use it to produce zero, one or more records fromeach input recordprocessed. or join) is applied to the result The transform() method is where we accept a record from the input topic. #transformValues(ValueTransformerSupplier,String)). cr173 hw4 fa14 I think we are done here! The `branch` function is used to split a KStream by the supplied predicates into one of more KStream results. Create a new KStream that consists of all records of this stream which satisfy Building Retry Architectures in Kafka with Compacted Topics | Matthew Zhou, V 2022 07 21 Confluent+Imply , Confluent 3, Event Streaming with Kafka Streams, Spring Kafka and Actuator. periodic actions can be performed. You can create both stateless or stateful transformers. (cf. Processor API is a low-level KafkaStreams construct which allows for: Using the Processor API requires manually creating the streams Topology, a process that is abstracted away from the users when using standard DSL operators like map(), filter(), reduce(), etc. Then we have our service's Kafka consumer(s) work off that topic and update the cache entries. java and other related technologies. kafka Also, using in-memory key-value stores meant that the Kafka Streams application left a minimal footprint on the Kafka cluster.
It can also become a necessity in situations when you have to adhere to quotas and limits. You are probably wondering where does the data sit and what is a state store. We needed something above what the Kafka Streams DSL operators offered. Here is a caveat that you might understand only after working with Kafka Streams for a while. These source code samples are taken from different open source projects. record-by-record operation (cf. type) of the output rec, Create a new KStream by transforming the value of each record in this stream However, there were still a few concerns to be addressed: Decoupling: We want to perform the computation and cache update in a separate work stream from the one that responds to the update request. The problem was that MySQL was locking the part of the index where the primary key would go, holding up inserts from other transactions. We need to buffer and deduplicate pending cache updates for a certain time to reduce the number of expensive database queries and computations our system makes. How can we guarantee this when the database and our job queue can fail independently of each other? The data for a single activity is sourced from over a dozen database tables, any of which might change from one second to the next, as our suppliers and staff modify and enter new information about our activities. A Kafka journey and why migrate to Confluent Cloud? 6 Benefits of Investing in Custom Software for Your Business, RFM NAV Customer Classification with Python and Azure Functions, Module 1 Final Project (Movie Industry Analysis). kafka apache In our case the value is a string of comma-separated language codes, so our merge function will return a string containing the union of the old and new language codes. https://kafka.apache.org/21/documentation/streams/developer-guide/dsl-api.html#transform-a-stream, Kafka Streams Tutorial with Scala for Beginners Example. However we are also immediately deleting records from the table after inserting them, since we don't want the table to grow and the Debezium connector will see the inserts regardless. In our case, we will do the following: It will ask you to implement 3 methods from Transformer interface: We should implement init(ProcessorContext context) and keep context, furthermore we should also get a state store out of it. if the instance goes down, it will not get rebalanced among other listening instances from the same group, only the original data (pre-transform) will. In this overview, hell cover: When providing information about activities for display on our website, our frontend teams have a few requirements: The data must be quick to retrieve, ideally with a single request, Some calculation and aggregation should already be applied to the data.
An additional changelog topic and a persistent KeyValue store meant more storage overhead on top of the repartition topic and slower startup times for the application as well since they had to read from this topic. and we tested the expected results for filters on sensor-1 and sensor-2 and a default. If the key is already known, the only thing we do is merge the new value with the existing one we have. Enjoy access to millions of ebooks, audiobooks, magazines, and more from Scribd. kafka stream processing javatpoint processors topology present major following there We need to simply call this function in our transform method right after the loop is done: You are probably wondering why transform returns null. APIdays Paris 2019 - Innovation @ scale, APIs as Digital Factories' New Machi Mammalian Brain Chemistry Explains Everything. I was deciding how and what goes to internal topic(s), and I had better control over my data overall. Kafka Stream Transformations are available from `KTable` or `KStream` and will result in one or more `KTable`, `KStream` or `KGroupedTable` depending on the transformation function. We are using a UUID as the primary key, which normally avoids this kind of lock contention since the distribution of new keys is pretty random across the index. We also need a map holding the value associated with each key (a KeyValueStore). A state store instance is created per partition and can be either persistent or in-memory only. This is For example, lets imagine you wish to filter a stream for all keys starting with a particular string in a stream processor. text in a paragraph. &stream-builder-${stream-listener-method-name} : More about this at https://cloud.spring.io/spring-cloud-static/spring-cloud-stream-binder-kafka/2.2.0.RC1/spring-cloud-stream-binder-kafka.html#_accessing_the_underlying_kafkastreams_object, Line 2: Get actual StreamBuilder from our factory bean, Line 3: Create StoreBuilder that builds KeyValueStore with String serde defined for its key, and Long serde defined for its value, Line 4: Add our newly created StoreBuilder to StreamBuilder. Sometimes the same activity receives updates seconds apart as our staff and suppliers make their changes. It has its pros and cons. This is great for reliability since our transformer can pick up right where it left off if our service crashes. Our first solution used Kafka Streams DSL groupByKey() and reduce() operators, with the aggregation being performed on fixed interval time windows. To populate the outbox table, we created a Hibernate event listener that notes which relevant entities got modified in the current transaction. To trigger periodic actions via We can do so as the aggregation results don't have to be persisted after they have been forwarded. Ill explain what we are doing line by line: Line 1: Get StreamBuilderFactoryBean using ApplicationContext based by a name. The challenges we faced with a time-based windowing and groupByKey() + reduce() approach indicated that it was not the most ideal approach for our use case. But, lets get started. Here we simply create a new key, value pair with the same key, but an updated value. 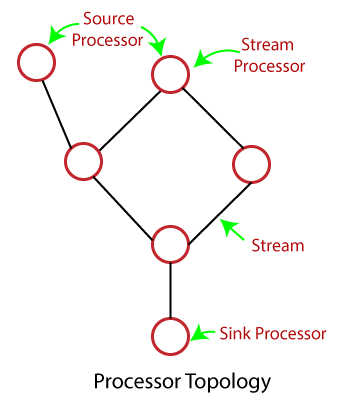{kind=link}
Furthermore, via It then uses Spring's TransactionSynchronization facility to trigger corresponding inserts to the outbox table right before a transaction is committed. Developers refer to the processor API when Apache Kafka Streams toolbox doesnt have a right tool for their needs OR they need better control over their data. This overhead meant that messages already having higher payload size, would leave an even higher footprint on the Kafka broker. RabbitMQ with fanout processing). The outbox pattern is a good fit for this task. Transforming records might result in an internal data redistribution if a key based operator (like an aggregation instance. We also want to test it, right? Call initializeStateStores method from our requestListener : We need to initialize our CustomProcessor in KStream .
{kind=link}
How did we move the mountain? This should be pretty simple. Github: https://github.com/yeralin/custom-kafka-streams-transformer-demo. VWO Session Recordings capture all visitor interaction with a website, and the payload size of the Kafka messages is significantly higher than our other applications that use Kafka. Marks the stream for data re-partitioning: we are using both `flatMap` from Kafka Streams as well as `flatMap` from Scala. Were going to cover examples in Scala, but I think the code would readable and comprehensible for those of you with a Java preference as well. can be altered arbitrarily). This kind of buffering and deduplication is not always trivial to implement when using job queues. 1. Otherwise, it will throw something along the lines with: Ooof. Lets add another method called findAndFlushCandidates: When we call findAndFlushCandidates , it will iterate over our state store, check if the cap for a pair is reached, flush the pair using this.context.forward(key, value) call, and delete the pair from the state store. Today, we will implement a stateful transformer, so we could utilize as much available features as possible. The Adaptive MACDCoding Technical Indicators. Your email address will not be published. the original values an, Transform each record of the input stream into a new record in the output stream Well, I didnt tell you a whole story. join with default ser, A Java virtual machine. Nevertheless, with an application having nearly the same architecture in production working well, we began working on a solution. To perform aggregation based on customerId, Our expectation of window-based aggregation was that for each key we would receive the results in the downstream Processor nodes strictly after the expiration of the window. In this Kafka Streams Transformations tutorial, the `branch` example had three predicates: two filters for key name and one default predicate for everything else.
stream kafka apache processing dzone api topology processor Instead of writing to a job queue for every request that updates the database, we insert an entry into another database table (called outbox) which contains a description of additional work that needs to be done (i.e. Hope these examples helped. kafka processor Feel free to play around with the code, add more payloads, modify aggregation logic. For our use case we need two state stores. Surprisingly, it comes from the name of our method annotated with @StreamListener i.e. org.hibernate.type.descriptor.java.BlobTypeDescriptor, org.hibernate.jpamodelgen.xml.jaxb.AccessType, org.hibernate.resource.beans.container.spi.ContainedBean, org.hibernate.cfg.annotations.reflection.XMLContext.Default, org.hibernate.resource.beans.container.spi.BeanContainer, org.hibernate.resource.beans.spi.BeanInstanceProducer, org.hibernate.type.descriptor.java.LocaleTypeDescriptor, org.hibernate.mapping.PersistentClassVisitor, org.hibernate.type.descriptor.sql.JdbcTypeFamilyInformation, org.springframework.messaging.rsocket.MetadataExtractor, Javatips.net provides unique and complete articles about Visitor Java class represents the input Kafka message and has JSON representation : VisitorAggregated Java class is used to batch the updates and has the JSON representation : The snippet below describes the code for the approach. Make it shine! The topic names, Group the records by their current key into a KGroupedStream while preserving Define following properties under application.properties : Should be pretty self-descriptive, but let me explain the main parts: Lets enable binding and create a simple stream listener that would print incoming messages: So far, so good! You can flush key-value pairs in two ways: by using previously mentioned this.context.forward(key, value) call or by returning the pair in transform method. All rights reserved. It is a little tricky right now in Spring Framework (and I hope they improve it later, but here is what I came up with). The SlideShare family just got bigger. Here is the method that it calls: Now we instantiate the transformer and set up some Java beans in a configuration class using Spring Cloud Stream: The last step is to map these beans to input and output topics in a Spring properties file: We then scope this configuration class and properties to a specific Spring profile (same for the Kafka consumer), corresponding to a deployment which is separate from the one that serves web requests. In the tests, we test for the new values from the result stream. SlideShare uses cookies to improve functionality and performance, and to provide you with relevant advertising. In Kafka Streams, these are called state stores and are actually Kafka topics themselves. Kafka Streams Take on Watermarks and Triggers, Programmatic Authentication under IAP on GCP. kafka streams semantics join the given predicate. Lets create a class CustomProcessor that will implement a Transformer
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
If it isn't, we add the key along with a timestamp e.g.
kafka hive queries Ill try to post more interesting stuff Im working on. Recently, the team was tasked with providing up-to-date aggregations of catalog data to be used by the frontend of the GetYourGuide website. Check out our open positions. In case of a consumer rebalance, the new/existing Kafka Stream application instance reads all messages from this changelog topic and ensures it is caught up with all the stateful updates/computations an earlier consumer that was processing messages from those partitions made. Love podcasts or audiobooks? To maintain the current state of processing the input and outputs, Kafka Streams introduces a construct called a State Store. The filter` function can filter either a KTable or KStream to produce a new KTable or KStream respectively. databricks
{kind=link}
{kind=link}
The provided The number of events for that customer exceeded a certain threshold. kafka tutorial The other initialization step is to set up a periodic timer (called a punctuation in Kafka Streams) which will call a method of ours that scans the queue from the top and flushes out any records (using ProcessorContext#forward()) that are due to be forwarded, then removes them from the state stores. dataiku All of this happens independently of the request that modified the database, keeping those requests resilient. In order to make our CustomProcessor to work, we need to pre-create our state store. Transitioning Activision Data Pipeline to Streamin What's inside the black box? Thats why I also became a contributor to Kafka Streams to help other maintainers in advancing this amazing piece of software. Copyright 2011-2021 Javatips.net, all rights reserved. Schedule actions to occur at strictly regular intervals(wall-clock time) and gain full control over when records are forwarded to specific Processor Nodes. How to add headers using KStream API (Java). So, when we had to implement the VWO Session Recordings feature for the new Data platform, Kafka was a logical choice, with Kafka Streams framework doing all the heavy lifting involved with using Kafka Consumer API, allowing us to focus on the data processing part. Before we begin going through the Kafka Streams Transformation examples, Id recommend viewing the following short screencast where I demonstrate how to runthe Scala source code examples in IntelliJ. Stateless transformations do not require state for processing. If you continue browsing the site, you agree to the use of cookies on this website. kafka Pros: when you make a continuous transformation and your instance(s) goes down, other instance (or after a restart) will pick up the work where it got left off. It deserves a whole new article, also pretty complex and interesting topic. His team's mission is to develop the services that store our tours and activities' core data and further structure and improve the quality of that data. into zero or more value, Creates an array of KStream from this stream by branching the records in the Lets create a message binding interface: Then assuming that you have Kafka broker running under localhost:9092 . which cache entries need to be updated). Now you can start our application, send some messages, and you should see that the messages are being received by our Kafka Streams listener. In this case, you would need state to know what has been processed already in previous messages in the stream in order to keep a running tally of the sum result. But what about scalability? But wait! and have similarities to functional combinators found in languages such as Scala. To process the inserts to the outbox table, we use Debezium, which follows the MySQL binlog and writes any new entries to a Kafka topic. Stateless transformers dont leave any memory or network footprints on brokers side, the transformation happens on the client side i.e. ProcessorContext. Free access to premium services like Tuneln, Mubi and more. Below is the code snippet using the transform() operator. Instead of directly consuming the aforementioned Kafka topic coming from Debezium, we have a transformer consume this topic, hold the records in temporary data structures for a certain time while deduplicating them, and then flush them periodically to another Kafka topic. In software, the fastest implementation is one that performs no work at all, but the next best thing is to have the work performed ahead of time. 3. I also didnt like the fact that Kafka Streams would create many internal topics that I didnt really need and that were always empty (possibly happened due to my silliness).
{kind=link}
{kind=link}
{kind=link}
Moreover, you can distribute (balance) the transformation work among instances to reduce the workload. A VirtualMachine represents a Java virtual machine to which this Java vir, A flow layout arranges components in a left-to-right flow, much like lines of
kafka rtd streams As previously mentioned, stateful transformations depend on maintainingthe state of the processing. With all these changes in place, our system is better decoupled and more resilient, all the while having an up-to-date caching mechanism that scales well and is easily tuned. You may also be interested in: How we built our modern ETL pipeline. Use it to produce zero, one or more records fromeach input recordprocessed. or join) is applied to the result The transform() method is where we accept a record from the input topic. #transformValues(ValueTransformerSupplier,String)). cr173 hw4 fa14 I think we are done here! The `branch` function is used to split a KStream by the supplied predicates into one of more KStream results. Create a new KStream that consists of all records of this stream which satisfy Building Retry Architectures in Kafka with Compacted Topics | Matthew Zhou, V 2022 07 21 Confluent+Imply , Confluent 3, Event Streaming with Kafka Streams, Spring Kafka and Actuator. periodic actions can be performed. You can create both stateless or stateful transformers. (cf. Processor API is a low-level KafkaStreams construct which allows for: Using the Processor API requires manually creating the streams Topology, a process that is abstracted away from the users when using standard DSL operators like map(), filter(), reduce(), etc. Then we have our service's Kafka consumer(s) work off that topic and update the cache entries. java and other related technologies. kafka Also, using in-memory key-value stores meant that the Kafka Streams application left a minimal footprint on the Kafka cluster.
{kind=link}
{kind=link}
It can also become a necessity in situations when you have to adhere to quotas and limits. You are probably wondering where does the data sit and what is a state store. We needed something above what the Kafka Streams DSL operators offered. Here is a caveat that you might understand only after working with Kafka Streams for a while. These source code samples are taken from different open source projects. record-by-record operation (cf. type) of the output rec, Create a new KStream by transforming the value of each record in this stream However, there were still a few concerns to be addressed: Decoupling: We want to perform the computation and cache update in a separate work stream from the one that responds to the update request. The problem was that MySQL was locking the part of the index where the primary key would go, holding up inserts from other transactions. We need to buffer and deduplicate pending cache updates for a certain time to reduce the number of expensive database queries and computations our system makes. How can we guarantee this when the database and our job queue can fail independently of each other? The data for a single activity is sourced from over a dozen database tables, any of which might change from one second to the next, as our suppliers and staff modify and enter new information about our activities. A Kafka journey and why migrate to Confluent Cloud? 6 Benefits of Investing in Custom Software for Your Business, RFM NAV Customer Classification with Python and Azure Functions, Module 1 Final Project (Movie Industry Analysis). kafka apache In our case the value is a string of comma-separated language codes, so our merge function will return a string containing the union of the old and new language codes. https://kafka.apache.org/21/documentation/streams/developer-guide/dsl-api.html#transform-a-stream, Kafka Streams Tutorial with Scala for Beginners Example. However we are also immediately deleting records from the table after inserting them, since we don't want the table to grow and the Debezium connector will see the inserts regardless. In our case, we will do the following: It will ask you to implement 3 methods from Transformer interface: We should implement init(ProcessorContext context) and keep context, furthermore we should also get a state store out of it. if the instance goes down, it will not get rebalanced among other listening instances from the same group, only the original data (pre-transform) will. In this overview, hell cover: When providing information about activities for display on our website, our frontend teams have a few requirements: The data must be quick to retrieve, ideally with a single request, Some calculation and aggregation should already be applied to the data.
{kind=link}